Distributed Search Engine
This is a class project for CIS 555 Internet & Web Systems (Spring 2021) at University of Pennsylvania.
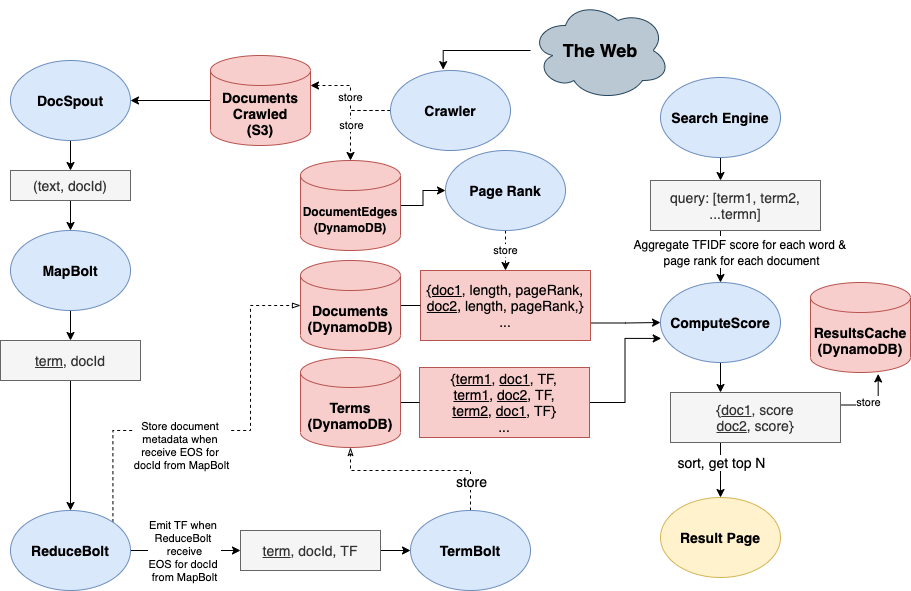
My team built a distributed search engine, with 4 components:
- Crawler is built with StormLite, a lightweight version of Apache Storm, and runs on EC2. It crawls webpages given a seed URL, maintains the frontier using SQS queue, respects protocols provided by domain specific
robots.txtand store content in S3 buckets. With three EC2 instances, the crawler can crawl 2-3 documents per second. For this project, we crawled 600k+ documents total. - Indexer is built with a MapReduce job implemented in Apache Storm, and runs on EC2. It reads document contents stored in S3 by the crawler and create an inverted index to be used by the search engine. The indexer processes each document into terms, and stores the inverted index on a table in DynamoDB for fast retrieval. The inverted index table provides term frequency (TF) and document frequency (DF) information for document ranking. With two EC2 instances, the indexer can index crawl 2 documents per second. For this project, we indexed 200k documents total.
- PageRank is built with Apache Spark and run on EMR cluster. It ranks the importance of each web page (or “document”) by constructing graphs from incoming and outgoing links.
- Search engine & UI is built with React.js for the front-end, Spark Java for the back-end. Given a query, the search engine retrieves documents all query terms appear in from the inverted index table, and rank them using TF-IDF and PageRank score to be displayed as the results page.
Using AWS cloud storage services such as S3 and DynamoDB, as well as Apache Spark, Apache Storm, Amazon EMR, all components are able to run in a distributed setting. I mainly worked on the indexer that reads document contents and create an inverted index to be used by the search engine and ranking algorithm.
See our project architecture below, and report here with implementation and optimizations details.